Last giveaway of the year!
I wanted to wrap up 2025 by giving back to the community. It’s been a busy year for me as a solo developer; I managed to release two brand new titles and finally finished a massive consolidation update for my puzzle series.
If you are looking for something new to play over the holidays, I’d love to share some promo codes. Just let me know which game interests you!
The New 2025 Releases:
+ Trivia Player: This is for the hardcore trivia fans. I built this because I was tired of multiple-choice quizzes that hold your hand. This is authentic trivia—real-time chat battles where you have to actually type the answer. No luck, just pure knowledge.
+ AI Movie Quiz: I used AI to generate unique, slightly twisted clips and images based on famous movies. You have to guess the film from the AI’s “dream.” It’s a surreal take on the classic movie quiz format.
The Big Update:
+ Subliminal Words: I spent a lot of time this year merging my other games (Subliminal Faces and Subliminal Football Quiz) into this one main game. It’s a visual puzzle game where words, faces, and objects are cleverly camouflaged in the image (think “Magic Eye” meets word search).
The Classics (Also available):
I also have codes left for my older arcade and puzzle games if you want to check out my back catalog:
+ Palindrome
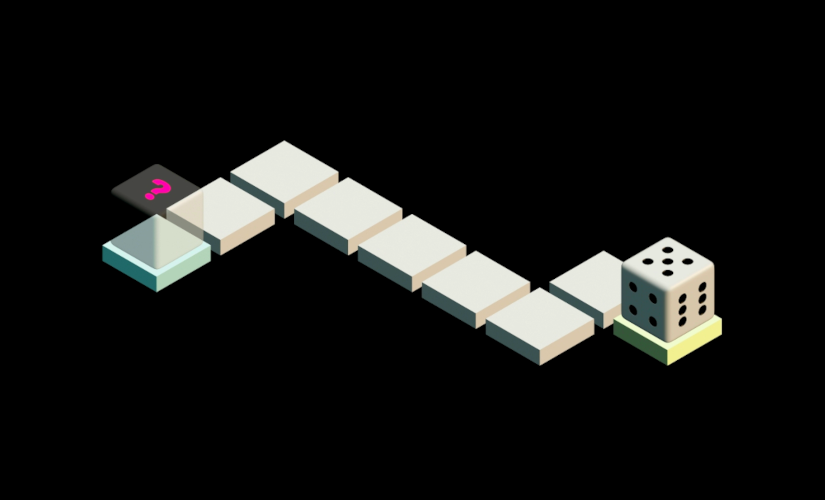
+ Dice Guess
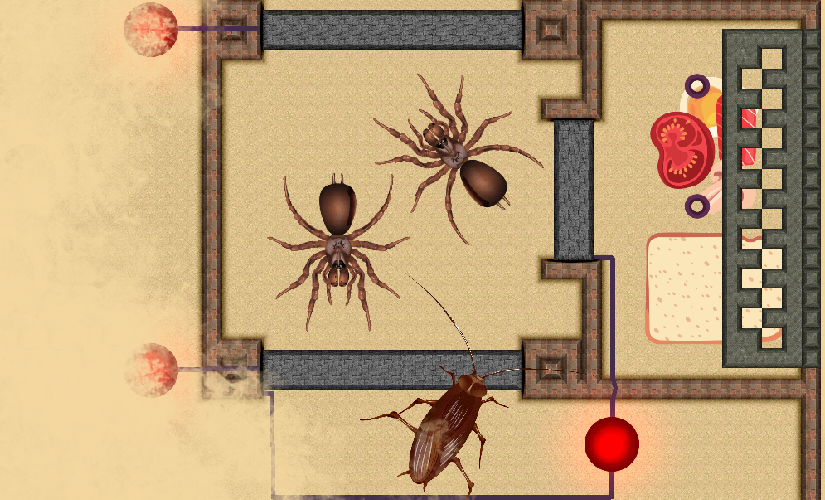
+ Snackroach
+ Penalty 2D
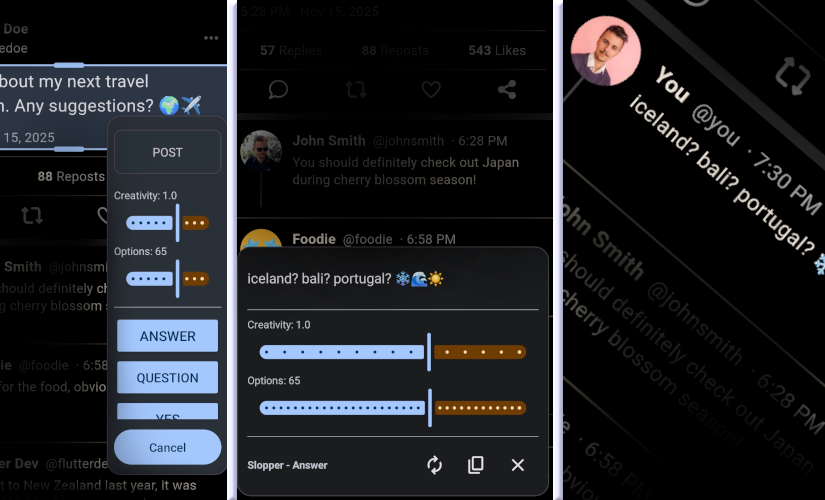
Also Slopper on Android!
How to get a code: Just send a mail to indrekl[at]gmail.com and tell me what code do you want and I’ll send you one while the supplies last!
Happy Holidays!
App Store Link
Google Play Link
regards,
🧑🎄